Hanna UI Based ImporterOverviewvMedia has the capability to programmatically import images that are in the Hanna format in addition to the option of dropping them in a folder and then running the import module manually in vMedia. The importer walks a directory tree and imports multi-page TIFF or PDF files. Indexing expressions are provided for the first-level folder name and TIFF or PDF file name. Optionally, you can specify a processing expression for the folder name and the file name elements. A processing expression is a function that is executed for the specified elements in the imported document. It is typically used to map fields within the vMedia database to data coming from an outside source. A processing expression can perform very sophisticated data transformation and formatting. Specifications
Configuring the Processing ExpressionsTo replace a vMedia database field with a data value derived from the source document, use this format: Fieldname WITH field value where fieldname is the name of the vMedia database field as specified in the data base configuration, and field value is the expression that will be evaluated when the document is saved. Within the field value, the following variables have special meaning:
STREXTRACT() Function for String ExtractionsNOTE: l_FileName will include the .PDF extension from the file name. To ignore the .PDF extension you can use the following command: strextract(l_filename,"",".") vMedia has a useful function to perform string extractions when the sub-strings are bound by specific delimiters. That function is called STREXTRACT() and it takes the following parameters (separated by commas):
There are some optional flags to modify function behavior: 1=Case blind delimiter search (for when the delimiter is an alpha string), 2=Ending delimiter may or may not be present, 4=Include delimiters in the returned sub-string Example:
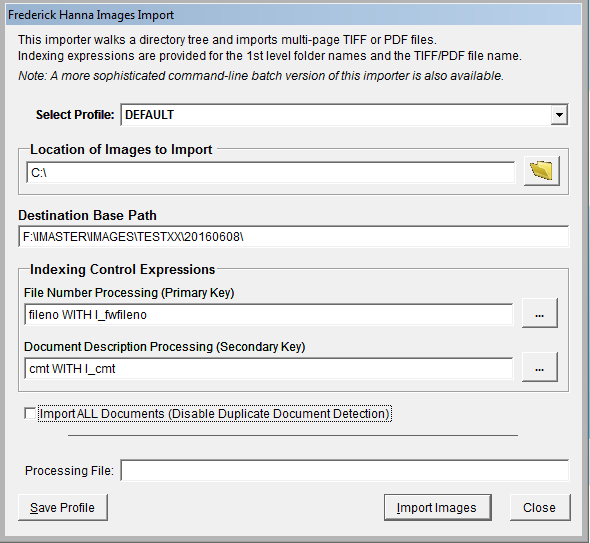
NOTE: This function can only be used in vMedia wherever an expression is allowed. "pFileName" is a variable for the Spectrum and Media Importers that corresponds to the name of the file being imported, including the extension. A similar variable for the Hanna Importer is "l_Filename", which is the file name without the extension. Procedure
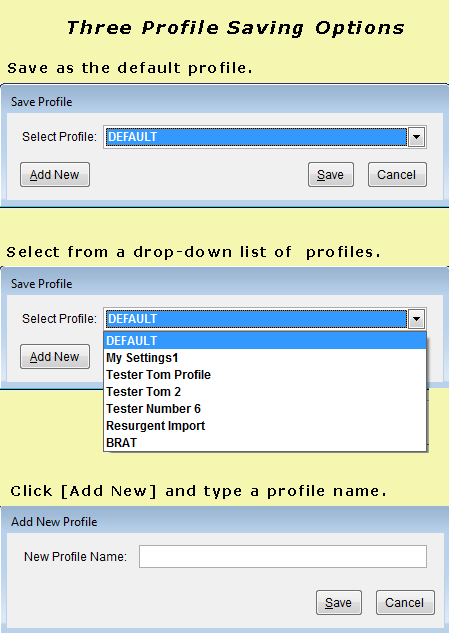
NOTE: Once a profile is selected, the desired profile will load. Focus remains with the profile selector after the load.
NOTE: Duplicate Document Detection is disabled by default. If you choose to uncheck this option, (as shown in the preceding graphic) the Duplicate Document Detection feature works with a specific field and index configuration only. Documents are considered duplicates if the Primary Key fieldname and the mandatory Secondary Key cmt both match an existing document. The requirements for the Duplicate Document Detection option are:
|